
Yes free lunch
A loophole in a fundamental theorem of machine learning suggests where AI is heading


1. Two philosophers walk into a bar
In 1814, Pierre-Simon Laplace conjured a demon.
In his Philosophical Essay on Probabilities, Laplace asked the reader to imagine an intellect so vast that it could know the precise position and momentum of every particle in the universe.
Such an intellect, he wrote, could calculate the future and reconstruct the past. Nothing would be uncertain. The arc of every billiard ball, the trajectory of every planet, the fate of every atom in every living body. All determined, all knowable.
For two centuries, Laplace’s demon was the reigning fantasy of scientific prediction. The only thing separating us from omniscience was information. Gather enough and the future opens like a book. It was seductive.
Decades earlier, a young David Hume wrote what he hoped would be the masterpiece of his generation.1
He asked the same question from the other end. If you are playing billiards, what evidence do you have that the next collision will behave like the last? What is stopping two colliding balls from shooting upward through the ceiling? Nothing but habit, he argued. A stubborn animal confidence that the world will remain as always.
Who was right?
I am a physicist by training, and so I tend to look at a problem and ask, am I seeing Laplace or am I seeing Hume?
The world we inhabit is mostly Laplacian. When you throw a ball, it has a predictable arc. What goes up, must come down.
But two centuries after Laplace, quantum mechanics would vindicate Hume's instinct. It turns out subatomic particles don’t behave the way Laplace insisted. Attempts by any intellect to measure their precise momentum and position will inevitably fail. And the ball you threw earlier? Even that has a momentum and position that can only be approximated. The arc only looks smooth to our eyes. Atomically, it’s bumpy.
The machine learning community takes lessons from both schools. Machine learning is an attempt to realize Laplace’s dream: acquire enough data about a system and you will understand it. But machine learning also wrestles with Hume’s warning: no amount of observations of the past guarantee a certain prediction about what comes next.
The tension between these ideas is where the fun is.
2. Exorcising demons
In 1996, another David (Wolpert), this time a physicist (we tend to propagate) tried to settle the argument with a theorem he called No Free Lunch.2
In a nutshell: If you apply every algorithm to every problem and average the results, they all perform the same. Whatever advantage an algorithm has on a particular problem, it pays for with equal disadvantage somewhere else. On average, a random forest or a neural network performs no better than simply flipping a coin. So much for Laplace’s demon.3
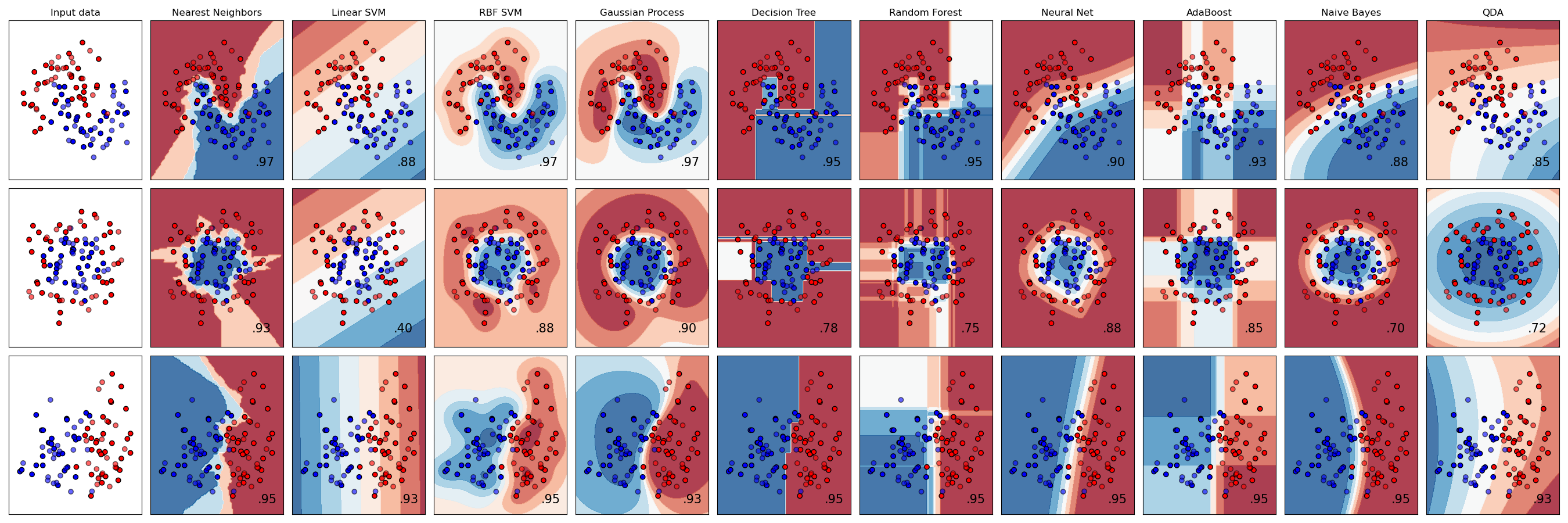
Wolpert’s findings implied that our human judgment about the structure of the world is a prerequisite to a machine’s capability; in other words, we need to pick the right algorithm for our data. We should be discerning, cultivate domain knowledge, do careful feature engineering, develop the right inductive bias. We cannot algorithm our way to brilliance.
This became the conventional wisdom of an entire field. It was reasonable, well-supported, and almost entirely correct.
3. When there’s no one else around to play with
On December 5th, 2017, Google DeepMind released a paper that should have started a philosophical crisis (but instead mostly started arguments about chess). They introduced AlphaZero, a program that taught itself to play by playing against itself.
The researchers didn’t prepare AlphaZero. They gave it no opening books, endgame tables, or grandmaster games to study. They offered no human knowledge of any kind. They only offered it a rulebook.
What AlphaZero did from there was generate visions of the future. It dreamed of possible, predictable outcomes. How its opponent (itself) might respond to a particular move or gambit. Using these visions, it could efficiently found what the best mode of action at any point in the game was.
Over and over again, it played itself across many digital multiverses.
After only nine hours of self-play it defeated the strongest chess engine, Stockfish, in the world. In 100 matches, it had 28 wins, 72 draws, and 0 losses.
It not only won convincingly, it played with style. When Stockfish chose a move, it searched over seventy million positions per second. AlphaZero searched only eighty thousand. But it compensated for this narrow lens by being radically selective. It only focused on the most promising variations. And it often sacrificed pieces for positional advantages.
Garry Kasparov, who had lost his own match against IBM’s Deep Blue two decades earlier, remarked, “I can’t disguise my satisfaction that it plays with a very dynamic style, much like my own!”

Stockfish was the product of decades of human refinement. Generations of programmers had poured their own understanding of chess into Stockfish’s handevaluation functions, opening databases, and endgame tablebases. It was a monument to the conventional wisdom of No Free Lunch: you match the algorithm to the problem. Human knowledge before the machine.
AlphaZero needed none of that. It started from random play and discovered strategy from scratch. It independently reinvented common openings before moving beyond them, into territory no human or machine had explored. Centuries of accumulated chess knowledge, reproduced and then surpassed, in less time than it takes to fly from New York to Moscow.
4. Are you talking to yourself?
In 2005, twelve years before AlphaZero, David Wolpert co-authored a follow-up paper called Coevolutionary Free Lunches. He proved that No Free Lunch had a critical exception: in self-play problems, where agents compete against each other to produce a winner, some algorithms will genuinely outperform others.
The exception condition is precise: when the objective, what “best” looks like, isn’t fixed, the geometry of the problem changes. The optimal solution space is instead formed by the dynamics of the agents’ play.

Soon, the AI field moved from games to language. By 2021, large language models were starting to provide plausible and convincing outputs. They ingested the internet and learned to recombine it, remix it.
Around this time a critique formed: the models were stochastic parrots, regurgitators of their training data and nothing more.4
My issue with the critique was not the diagnosis, it was its poor assumptions; one, that learning is, in its basest form, memorization with extra steps. Two, that how we trained models was a fixed paradigm. Three, that the ceiling of machine intelligence would always be bound to the corpus it consumed, the human input.
In 2022, OpenAI published the InstructGPT paper. In it are results that should have settled the debate. They demonstrated that a tiny model, only 1.3 billion parameters, was preferred over a 175 billion parameter model. The vital difference: though both models shared the same pre-trained foundation, the tiny model was refined using human feedback, the larger trained to mirror human instruction.
The differentiator was not more data. The objective had changed. It was a dialogue between a person and a machine.
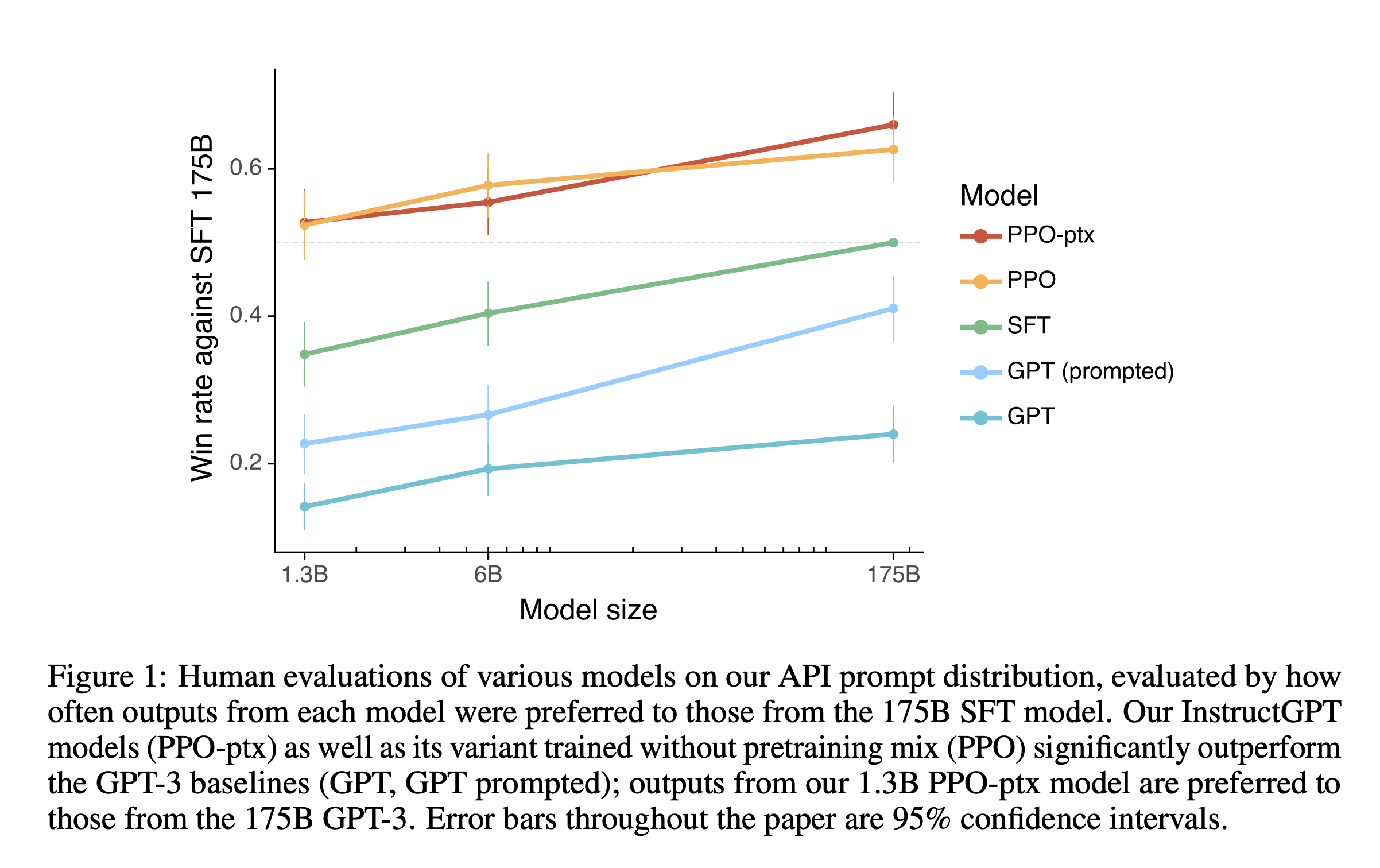
This was the birth of reinforcement learning for language modeling; rote memorization gave way to a more human-centered optimization function.
In this paradigm, the stochasticity of the model was a benefit, not a drawback. You can prompt for a variety of outputs, have people rank them, and then train the model to generate outputs closer to their preferences.
This seemed enough to transform a parrot into something that had an implicit understanding of intent. A model that responded with coherence outmatching something 100 times its size.
The field was learning something critical: reinforcement enables transformation. It’s where the model learns to play.5
AlphaZero demonstrated the principle in its purest form. It was not memorizing, it was playing among potentialities. The InstructGPT paper showed that the same primitive, feedback-as-learning-engine, could be applied to language.
Once you understand that, the next question must be, what else can we play?
5. Congratulations, you just played yourself
The superhuman capabilities of these models are real. When a coding agent can refactor with a coherence that surprises experienced engineers, I don’t think this leap comes from a bigger corpus or a longer context window. Does it come from self-play?

Imagine a system that generates its own coding problems and attempts its own solutions. It or another capable model evaluates the work. It encounters edge cases, failure modes, architectural dead-ends. It creates a portfolio that rivals what thousands of engineers could do in their lifetimes. It is playing chess with software engineering.
Where else could we apply this pattern? Consider security. In the old paradigm, you train on a dataset of known vulnerabilities and hope the model generalizes. In the self-play paradigm, you generate attack vectors that have never existed in the wild. The system explores the space of possible attacks and discovers new ones through adversarial play. It encounters and handles scenarios that no human red team would think to construct.
Medicine is the domain where this pattern is most needed and least proven.
Chess has perfect information, known rules, unambiguous win conditions. Medicine has none of those things. You don’t always know the root of the problem. The rules change between patients. A treatment that works for one person may harm another. But if we could simulate the full care journey, a doctor making decisions, a disease responding, outcomes unfolding, if we let the system play through a trillion variations, would it learn things that no clinical trial could reveal?
When language models entered the mainstream, people figured out that they could handle a lot of problems if we could describe them as a prompt. What problems could we solve if we could structure them for self-play?

6. Towards the divine
Is Laplace’s demon smarter than us? No. The ability to map all potential futures of a system is not what makes human intelligence special.
Humans know that the world is not deterministic, we do not interact with it as though it were. We infer. We guess. We learn enough to draw the shape of something and then we act upon it.
It’s with that same intuition that we designed these playgrounds. The choice of what to simulate, what dynamics to introduce, what objectives to optimize. This is where human intuition is vital. A thousand naive algorithms left to their own devices would not invent self-play.
The hard part is bringing self-play to problems that don’t look like games. I want to stop asking what data should I feed it? and instead ask what world should we build for it to grow up in?6
Because we are not building tools anymore, we are raising something. The frontier of intelligence is not compute or data or architecture. It is the careful, creative work of deciding what form of intelligence we want to cultivate, then building the playground where it can teach itself things we never could. What it becomes depends on the world we give it to explore.
When my son was born, the first thing we put in his room was a milk crate full of picture books. On the wall, we hung a picture I’d taken of a gorilla at the Bronx Zoo. Shortly after his first birthday, he held up a book to show me a silverback inside. He then pointed at the wall and smiled. “Dada. Gorilla.”
A Treatise of Human Nature (1739).
David H. Wolpert and William G. Macready co-authored No Free Lunch Theorems for Optimization in 1997. Wolpert published an earlier version for machine learning in 1996. The optimization paper is the one most often referenced.
Wolpert opened his No Free Lunch paper with a quote from Hume’s A Treatise of Human Nature (1739). The connection between the problem of induction and the limits of machine learning was not lost on him.
Bender, Gebru, et al.’s 2021 paper raised important concerns beyond technical capability, including environmental costs, bias in training data, and exploitative data labor. I’m engaging specifically with the claim about what these models can and cannot learn.
I’m using “play” poetically here. RLHF is not self-play in the strict Wolpert sense, where two agents compete to produce a champion. But the shared primitive is that the objective function is no longer fixed, it emerges from interaction. Constitutional AI, where one model evaluates another against a set of principles, moves closer to true self-play.
Yann LeCun has argued that the next leap in AI will come from systems that build internal representations of how environments work, or world models. His proposed architecture, JEPA, is designed for this from the ground up. What this essay presupposes is that a different path could lead to the same destination: world models emerging from self-play, regardless of the architecture. Read more about LeCun’s vision here: “A Path Towards Autonomous Machine Intelligence” (2022).
Thank you to Paul Ledbetter for the conversations that inspired this post.